
Quality-Diversity (QD) is a family of evolutionary algorithms that generate diverse, high-performing solutions through local competition. The key idea is that solutions should only compete with similar solutions, not the entire population. This insight, inspired by natural evolution, is what distinguishes QD from traditional evolutionary algorithms.
What makes solutions "similar"? That's defined by a descriptor space, a set of features that characterize how a solution behaves, separate from how well it performs. For a walking robot, descriptors might be foot contact patterns or gait style. For generated images, descriptors might be visual features like pose, lighting, or style. QD algorithms maintain diversity across this descriptor space while optimizing performance.
While research has focused on improving specific aspects of QD algorithms, surprisingly little attention has been paid to the core mechanism itself. Most approaches implement local competition through explicit collection mechanisms (fixed grids in MAP-Elites, or unstructured archives in Novelty Search) that impose artificial constraints requiring predefined bounds or hard-to-tune parameters.
Dominated Novelty Search takes a different approach. We show that QD methods can be reformulated as Genetic Algorithms where local competition occurs through fitness transformations rather than explicit collection mechanisms. DNS implements a novel competition strategy that dynamically adapts to the shape and structure of the descriptor space, eliminating the need for predefined bounds, grid structures, or fixed distance thresholds.
DNS is a drop-in replacement for the grid mechanism in MAP-Elites that:
- Matches or outperforms existing approaches on standard QD benchmarks
- Works in high-dimensional descriptor spaces where grids are impossible
- Requires no discretization, bounds, or threshold tuning
- Adapts to a potentially changing descriptor space as evolution unfolds
- Is available in QDax and PyRibs, or can be implemented from scratch in ~10 lines of code
2. The Problem with Grids
MAP-Elites, the most popular QD algorithm, works by dividing the descriptor space into a grid. Each cell holds exactly one solution, the best one found for that region. This is elegant and simple, but it comes with fundamental limitations.
Grids don't scale. A 10×10 grid in 2D has 100 cells. Add a third dimension and you have 1,000 cells. With 10 dimensions, you need 10 billion cells. With the 512-dimensional CLIP embeddings we use in our experiments? You'd need $10^{512}$ cells, more than the number of atoms in the observable universe.
Grids need bounds. Traditional QD algorithms require you to specify bounds in advance, like "poses range from -90° to +90°" or "lighting ranges from dark to bright." But what if you don't know the bounds? What if you're working with learned embeddings like CLIP where dimensions have no human-interpretable meaning?
Grids lose information. Forcing continuous descriptor spaces into discrete cells throws away information. Two solutions at opposite corners of the same cell are treated as "the same location," even though they might be quite different. This limits the granularity of diversity that can be achieved.
3. The Algorithm
QD algorithms are really just genetic algorithms with special fitness functions. The "local competition" that makes QD work can be implemented by transforming fitness values before selection. This means a simple fitness augmentation to a standard GA can give you a population-based QD algorithm that outperforms MAP-Elites without any grids or archives. That's exactly what DNS does.
Dominated Novelty Search implements local competition through a simple idea: a solution's survival depends on how different it is from the solutions that outperform it. If there's a better solution nearby in descriptor space, you're in trouble. But if you're doing something different from everyone who's better than you, you get to stick around.
3.1. The Competition Function
Both MAP-Elites and DNS can be understood as genetic algorithms with different competition functions that transform fitness values before selection. Here's how they compare:
- Each solution $x_i$ is assigned to its nearest centroid based on its descriptor, partitioning the population into grid cells.
- Within each cell, only the highest-fitness solution $x_k$ maintains its fitness $\tilde{f}_k = f_k$. All others are eliminated: $\tilde{f}_j = -\infty$ for $j \neq k$.
Requirement: Predefined grid with known bounds.
- For each solution $x_i$, compute distances to fitter solutions: $D_i = \{\|d_i - d_j\| \mid f_j > f_i\}$.
- Compute dominated novelty $n^+(x_i)$: the average distance to the $k$-nearest-fitter neighbors. Set $\tilde{f}_i = n^+(x_i)$.
Requirement: None. Works in unbounded, continuous spaces.
The key insight: MAP-Elites discretizes space and keeps one winner per cell. DNS computes distances to better solutions and rewards being far from them. No grid, no bounds, no discretization.
The intuition is simple: you get eliminated if there's a better solution nearby. To be discarded, two conditions must hold: (1) a solution with higher fitness exists, AND (2) it's close to you in descriptor space. If either condition fails, you survive.
- Survive by being good: If no one nearby has higher fitness than you, you're safe. This includes being the global best, but also just being the best in your local neighborhood.
- Survive by being different: Even if better solutions exist, you survive by being far away from them in descriptor space. The farther you are from your $k$ nearest fitter neighbors, the higher your competition fitness.
Solutions that contribute neither quality nor diversity, those that are both worse AND similar to better solutions, are eliminated.
3.2. The Full Algorithm
The complete DNS algorithm follows the standard QD framework, with the competition function replacing traditional grid or archive mechanisms:
- Initialize: Population $\mathbf{X}$ with fitness $\mathbf{f}$ and descriptors $\mathbf{d}$
- While not converged do:
- Reproduce: Generate $B$ offspring using genetic operators
- Concatenate: Add offspring to existing population
- Evaluate: Compute fitness and descriptors for all solutions
- Compete: Transform fitness via competition function (Algorithm 1)
- Select: Retain top-$N$ individuals by competition fitness $\tilde{f}$
- Return population $\mathbf{X}$
The parameter $k$ controls the locality of competition. Small $k$ (like 3) means very local competition: you only need to be different from your immediate neighborhood. Large $k$ means broader competition: you need to be different from many better solutions.
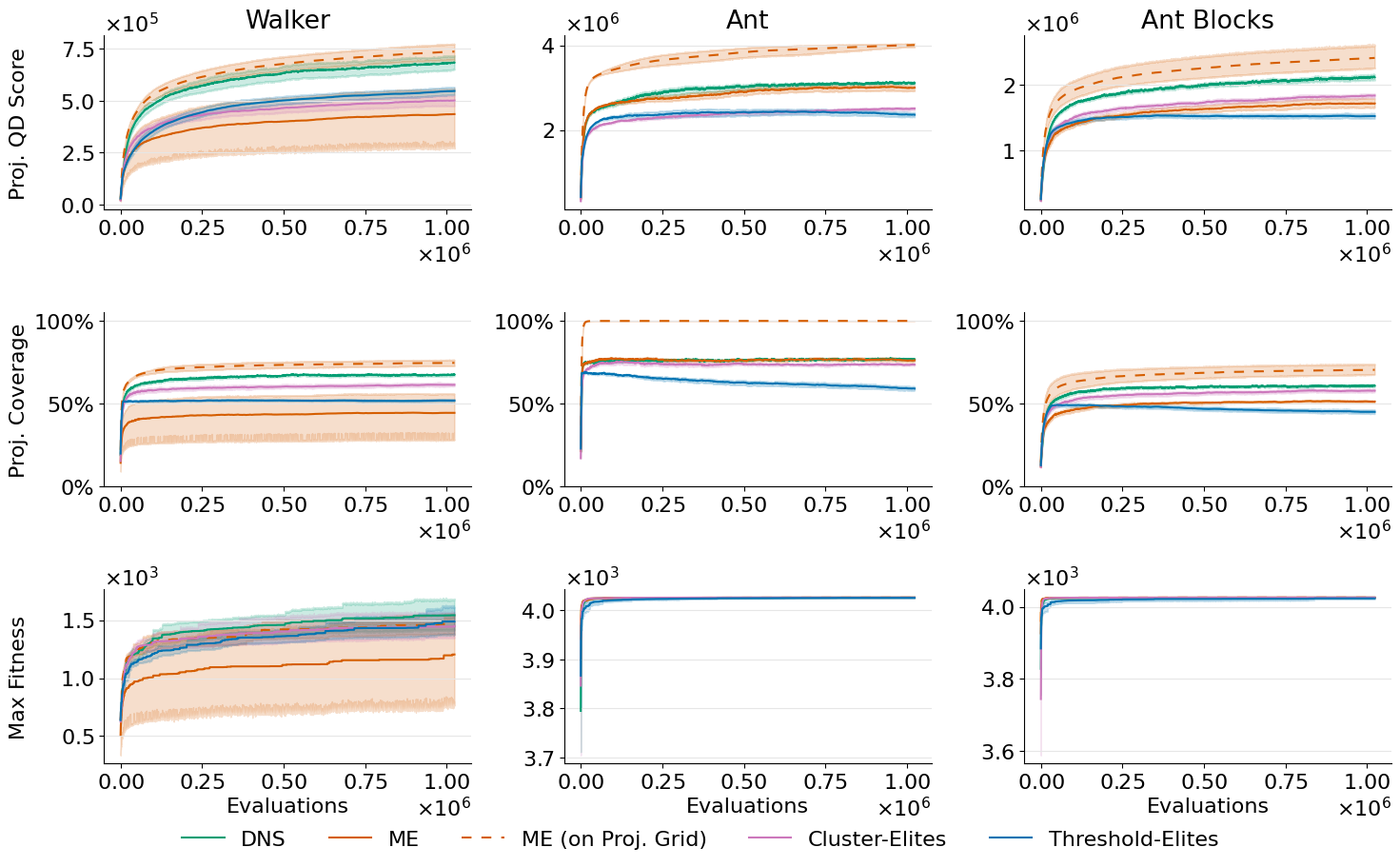
4. Benchmark Results
On standard continuous control benchmarks, DNS matches or outperforms MAP-Elites, particularly in environments where the reachable descriptor space doesn't align neatly with a grid. Full details are in the paper.
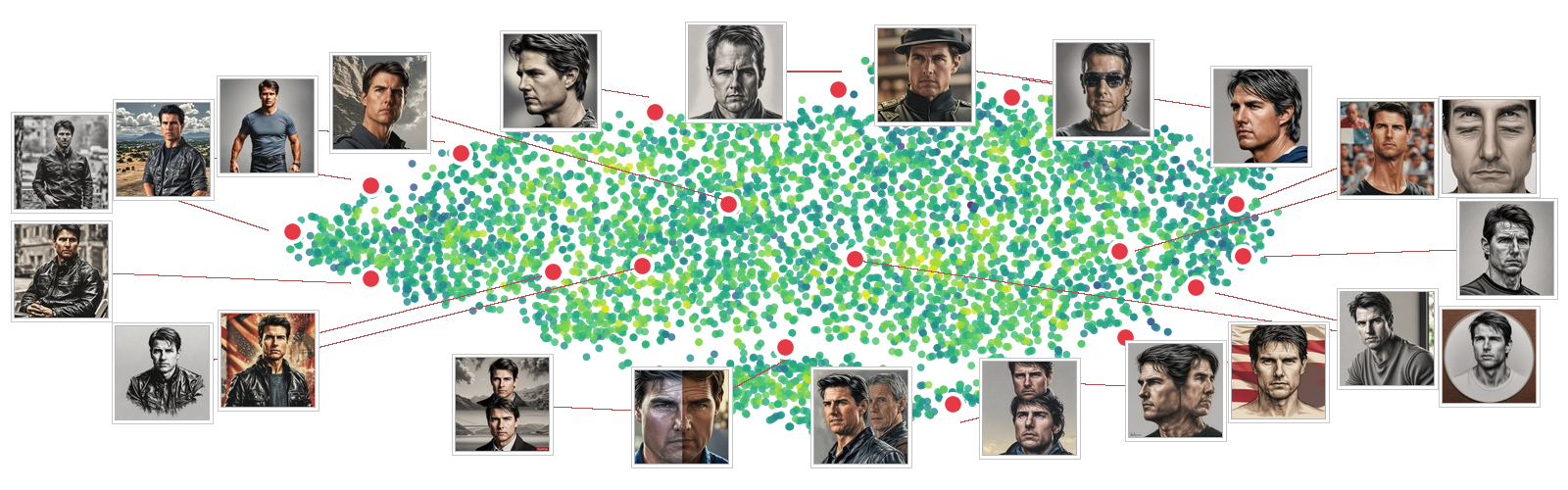
5. Scaling to High-Dimensional Descriptor Spaces
Standard benchmarks use 2-4 dimensional descriptor spaces where grids are feasible. But what happens when we push into territory where grids become impractical?
5.1. The Kheperax Maze Challenge
We tested DNS on Kheperax, a maze navigation task where agents must traverse complex mazes. Unlike traditional maze tasks that only consider final position, we characterize behavior using the agent's entire trajectory through the maze.
By sampling the agent's position at $n$ evenly-spaced intervals, we create descriptors with $2n$ dimensions. With $n=30$ trajectory points, we get a 60-dimensional descriptor space. This trajectory-based approach captures richer behavioral information, but creates significant challenges for grid-based methods.
5.2. Scaling with Dimensionality
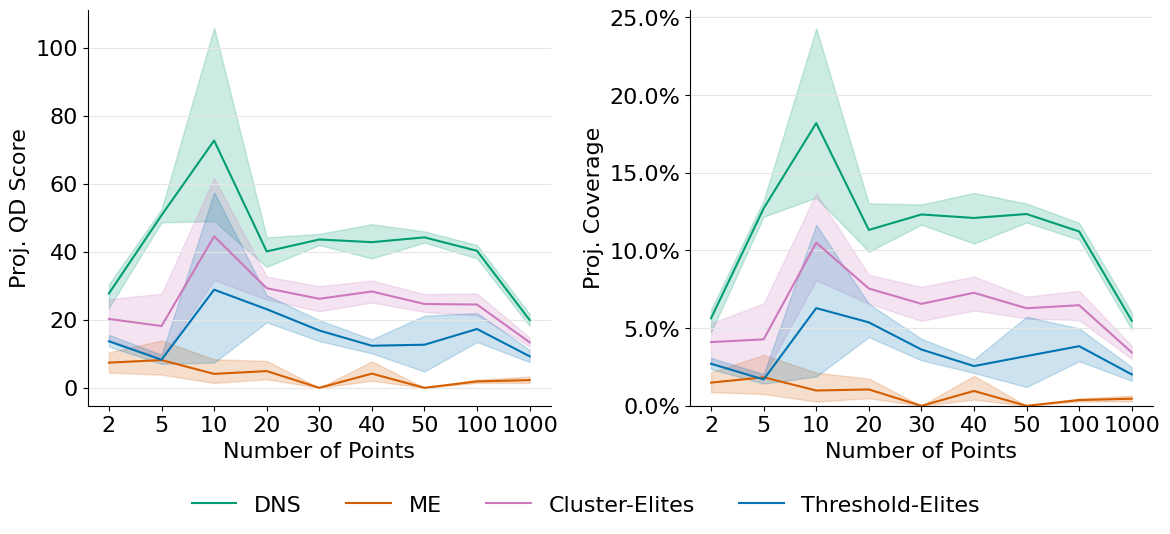
The results show that DNS maintains strong performance as dimensionality increases, while MAP-Elites suffers from discretization inefficiencies. DNS can adapt its search to the currently reachable portions of the descriptor space, leading to more effective stepping-stone discovery even in high dimensions.
5.3. Unsupervised Descriptors
What if you don't know the descriptor space at all? In unsupervised QD (following the AURORA algorithm), descriptors are learned as low-dimensional embeddings during evolution. The space changes as the algorithm runs, making predefined bounds impossible.
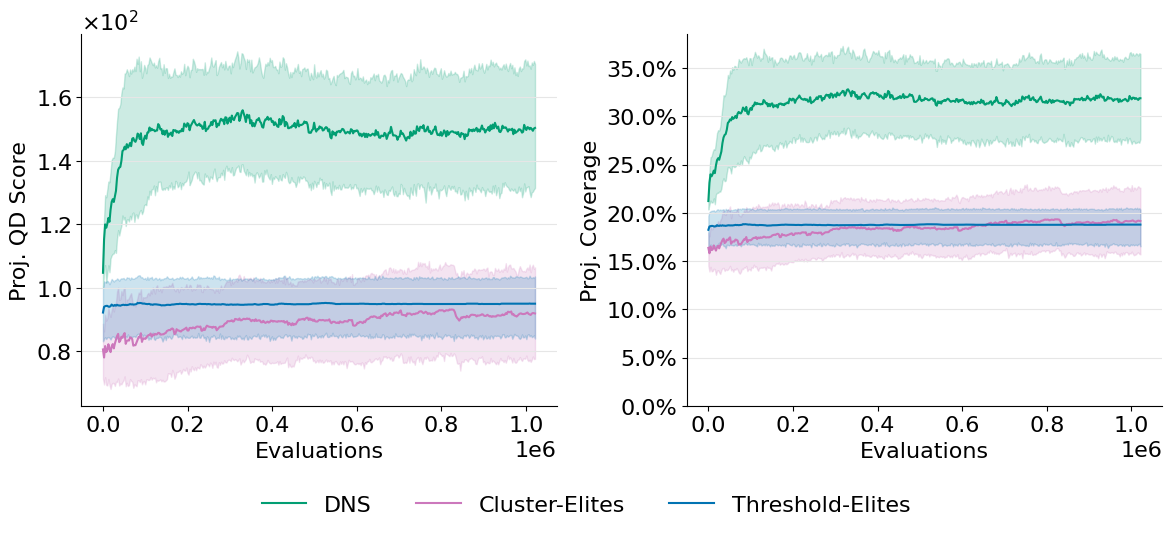
This is where DNS truly shines: it adapts to learned descriptor spaces that are unbounded and changing throughout evolution. MAP-Elites, which requires predefined grids, simply cannot be applied in this scenario. Threshold-Elites requires complex container size control mechanisms, while DNS achieves strong performance with its simple competition mechanism.
6. What This Means for QD
The fundamental innovation of QD algorithms is not their collection mechanisms (grids, archives) but rather how they transform fitness based on local competition. DNS makes this explicit by replacing collection mechanisms entirely with a fitness transformation.
This has several implications:
- QD in high dimensions: DNS enables QD in descriptor spaces where grids are impossible. This opens up applications using learned embeddings (CLIP, DINO, etc.) as diversity measures.
- Unsupervised QD: When descriptors come from a learned model (like an autoencoder or CLIP), the descriptor space itself changes as the model updates. DNS handles this naturally: it doesn't need fixed bounds or a predefined grid, so it can illuminate the descriptor space even as the underlying representation shifts. This enables fully unsupervised QD where both the quality measure and the diversity measure are learned.
- Enabling open-ended evolution: Open-ended systems require algorithms that work in unbounded, changing descriptor spaces. DNS meets these requirements: it needs no predefined bounds, adapts to learned embeddings that shift during evolution, and scales to high dimensions where grids are impossible. Leniabreeder demonstrates this in practice, using DNS to generate unbounded diversity in artificial life.
- Simpler implementations: No grid management, no archive structures, no discretization logic. Just a fitness transformation and standard evolutionary selection.
6.1. DNS in the Wild: Leniabreeder
DNS has been used in Leniabreeder, a framework that automatically discovers diverse self-organizing patterns in Lenia, a continuous cellular automaton that produces lifelike artificial creatures.
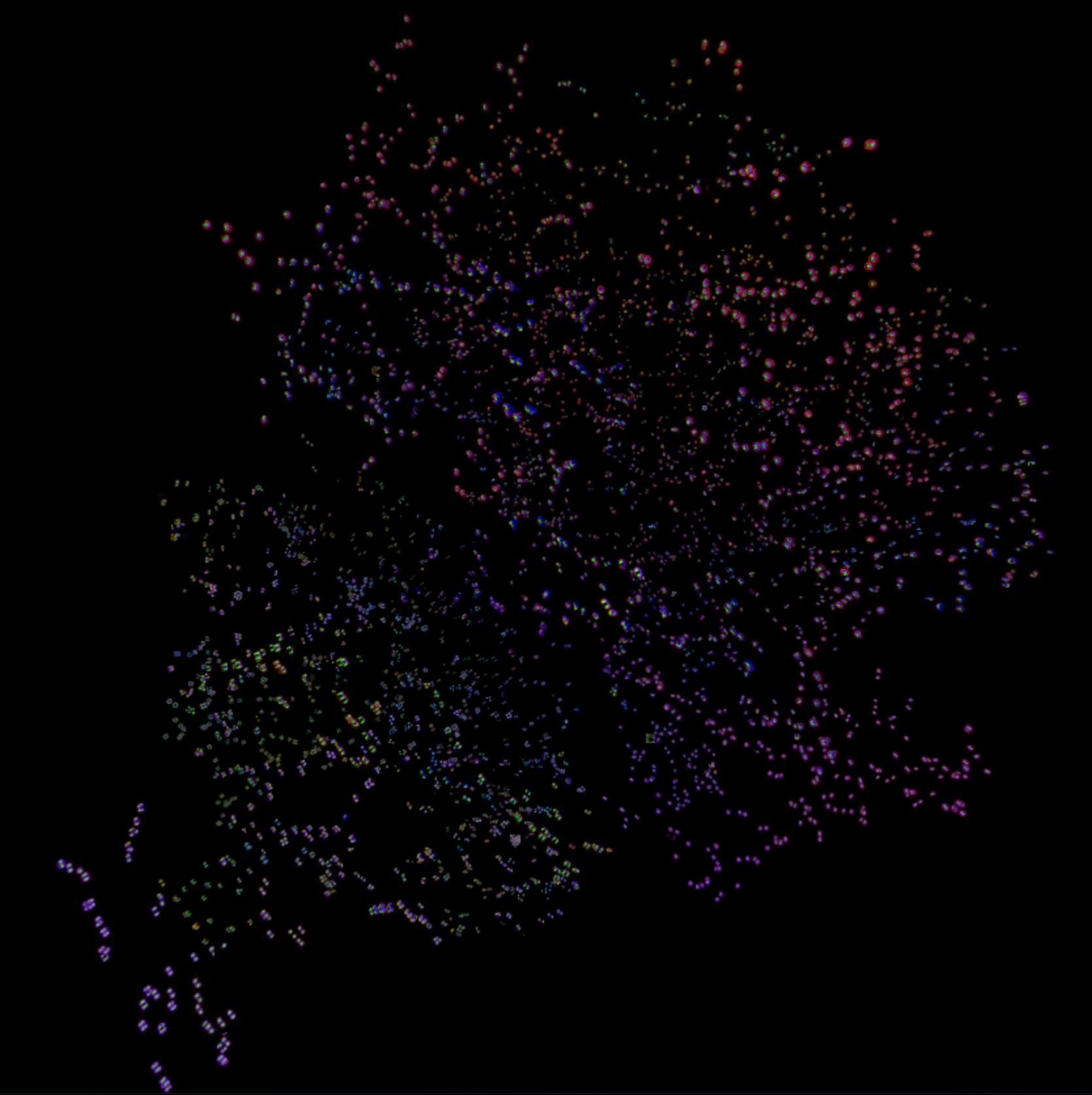
By evolving in learned embedding spaces, Leniabreeder can discover patterns that weren't anticipated in advance. This is exactly the kind of open-ended exploration that DNS enables: no predefined grid, no fixed bounds, just evolution adapting to whatever structure emerges.
6.2. The Best of Both Worlds
Where does DNS sit in the landscape of evolutionary algorithms? On a set of black-box optimization tasks, we can measure both the fitness and novelty of final populations. DNS achieves the best of both worlds: near Novelty Search levels of diversity while maintaining near GA/MAP-Elites levels of performance.

7. Conclusion
The MAP-Elites grid served QD well for over a decade. But as we push toward higher-dimensional descriptor spaces and truly open-ended evolution, the grid becomes a limitation rather than a feature.
Dominated Novelty Search offers a path forward: the same local competition principles that make QD powerful, without the artificial constraints of discretization. It's a drop-in replacement that performs better, scales better, and adapts to whatever descriptor space your problem requires.
The grid is dead. Long live Dominated Novelty Search.
References
[1] Bahlous-Boldi, R., Faldor, M., Grillotti, L., Janmohamed, H., Coiffard, L., Spector, L., & Cully, A. (2025). Dominated Novelty Search: Rethinking Local Competition in Quality-Diversity. Proceedings of the Genetic and Evolutionary Computation Conference (GECCO). arXiv:2502.00593
[2] Mouret, J.-B., & Clune, J. (2015). Illuminating search spaces by mapping elites. arXiv preprint arXiv:1504.04909.
[3] Lehman, J., & Stanley, K. O. (2011). Abandoning objectives: Evolution through the search for novelty alone. Evolutionary Computation, 19(2), 189-223.
[4] Fontaine, M. C., & Nikolaidis, S. (2023). Differentiable Quality Diversity. NeurIPS.